
Mr·Jax LV
发表于 2025-4-9 13:38:20
NLP是和搜广推类似的业界主流MLE方向之一,最近两年因为大火的LLM以及高薪岗位的加持,很多同学决定转向这个领域,下面我结合一位学员的亲身经历来聊一聊NLP方向的入门:
先说背景,美本+CMU硕,谷歌7年工作经验,经贾老师指导后端转LLM约半年,之前给同学分享过我OpenAI的面经, 群里很多人说能拿到面试就已经很厉害了,可以说虽败犹荣吧。
大牛学院:OpenAI挂经:谷歌工程佬被嫌弃的一生欢迎大家加我的个人微信交流:GoogleXu01
加群找贾老师:MSFTJustin
大牛学院:北美求职Timeline以及保offer项目介绍
这里再给大家分享一下我转NLP的学习路径以及我转型半年后的心得,希望对大家有帮助。
自然语言处理,它就是一个教导机器去用我们人类的方式理解和交流的过程。也就是“说人话”,不管是什么语言。NLP在过去这几年这么火,表面是LLMs取得了0到1的突破,其背后其应用的广泛程度。NLP就像站在一个多领域交汇的路口,融合语言学,用于评估的计算机科学,语言学统计概率和数据,用于预测的机器学习算法,人工智能等等。我们现在看到了很多LLMs的产业化和应用,但是它们仍然存在很多提升的技术细节,比如幻觉问题,长文本理解记忆问题,这些追根溯源,都是NLP问题。然而NLP的算法和研究问题庞杂,想了解学习的同学往往望而却步。那么我就以一个尽量贴近实际应用的方式,来帮助没接触过NLP的同学有一个入门级别的认识。
NLP pipeline 不同于传统的机器学习,他的数据只有文字,且标注非常不清晰,会有很多的复杂情况:
- 俚语Slang
- 习惯用语Idioms
- 变化的句子结构(倒装等)Variations in sentence structure
这需要更多的准备工作从而进行分析。这个过程不是一个简单的从A点到B点的过程,而是像下图所示的一样,有数不清的目的地,和非常多的选择来到达,当然这中间就也会有歧路让你偏离你的目的。
一个NLP模型的实现过程就像下图所示的流程,分为5个部分
- 数据采集和数据增强Data Acquisition & Data Augmentation
- 文本预处理Text Pre-processing
- 特征工程与建模Feature Engineering & Modeling
- 性能分析Analyzing Performance
- 部署和持续监控Deployment & Ongoing Monitoring
数据采集和数据增强Data Acquisition & Data Augmentation
这一阶段的关键就是数据,这是每个NLP模型,也是现在大模型的根本竞争基础。我们需要找到高质量,符合我们目标的数据。这些数据的来源可以是一些公共文本库(Public text corpus),比如一些政府公开的数据,公开分享的书籍文章。也可以是一些私有数据(Internal data),比如一些医院的诊疗记录,会计分析和律师所的一些内部分析文件。 你可能迫不及待的要去进行下一步,但是直接获取高质量的数据在实际中非常理想。很多时候会出现数据量不够多,或者错漏较多。那我就需要对数据进行优化(Augmenting)。最常见的方式是通过其他信息来补充数据,来让他内容更丰富。或者我们还可以对数据进行一定形式的转换(Data transformation),让数据能够更好的服务于我们的实际需求和应用。
文本预处理Text Pre-Processing
下一步就是进行文本的预处理。我觉得这一步我们可以想象成为一个长期旅行做准备。在传统的机器学习,这一步要做是清理数据,处理一些异常和缺失的信息。但是对于NLP问题来说,因为是针对于文本信息,我们需要做的事情其实是更多的。比如说我们拿到了新闻文章的一个数据集,我们需要对数据集做的,就包括要理顺标点符号和缩写,删除一些没有意义的词汇(Stop words),以及一些名称的调整。还有一些时候,由于我们的语言中的很多词句在不同情境下有不同含义,所以我们可能需要做词义消歧(Word Sense Disambiguation),来搞清楚文本实际表达的意思。 其实还有很多准备工作,我就不一一列举了。就说其中一个例子,就是当我们用网上用户发布的内容来做数据集。比如,我们在一个网站上抓取产品的反馈,我们需要把html文件中所带的tag都拿掉。还有一些Unicode 以及表情符号,错别字,都需要进行处理。
特征工程与建模Feature Engineering & Modeling
经过数据的处理之后,我们就可以进行模型算法的使用了。还是把这个NLP整个的构建的过程想象成旅行,这一步我们就来到了一个路口。有了上面做好的旅行准备————干净高质量的数据集,我们现在该选择一条路了。这一步就是需要我们使用一些算法模型来进行文本分类、揭示理解主题、提取信息、做出预测。
对于文本分类,我们可以直接使用一些很传统的方式像朴素贝叶斯或逻辑回归(需要把text转换为数字类型数据)。对于其他步骤,我们就要用到一些专门用于NLP的算法,比如Word2Vec用于词汇的嵌入,语言模型用于文本的生成。这也是我们如今能看到的各大语言模型LLMs。
性能分析Analyzing Performance
下一步我们就要进行模型的测试和分析。这一步相当重要,能让我们知道我们的模型能力———到底能不能有用户为其付费。根据我的经验,因为很多时候这些文本信息是没有标签的,但是如果在这一步评估的时候,我们发现我们的模型需要带标签的数据集,那么我们就要重新来回到整个流程的开始,在第一步中,给我们的文本制作标签或者获取一个已经带标签的数据集。在评估这一步的关键是不能只追求一个统计指标的水平,比如我就要对于书本主题预测的准确性(Accuracy),我们需要看整体的一个综合维度表现(Metric)才能对模型的能力进行充分的了解。这一步对于落地的产品应用相当重要,因为他关系着我这个模型是否能真正参与到一个项目的进程。比如在金融经济领域,这些综合维度对一个商业投资的选择或一个宏观过程的预测才有影响。
如果你自己尝试,你会发现第一版的模型大概率都会失败。不要灰心,基本都是这样。这个时候你需要不断进行算法模型的调整迭代+评估+数据优化这一过程。
部署和监控Deployment & Ongoing Monitoring
来到这一步,说明你的模型已经达到你的预期目标了!恭喜,你距离你的语言模型就差最后一步。将模型进行部署发布,你的产品就能够获得关注个使用。但是其实还有没有完,我们需要对模型进行长期的监控,确保他的准确度和效率保持在一个不错的水平。我们可以通过这些反馈,来调整修正模型,保证产品质量的稳定性,增加其价值。
说到这,我想你已经了解了一个NLP模型开发的过程了。我通过一个实际的例子来通俗的回顾这个流程(也是个面试题),加强这个理解。
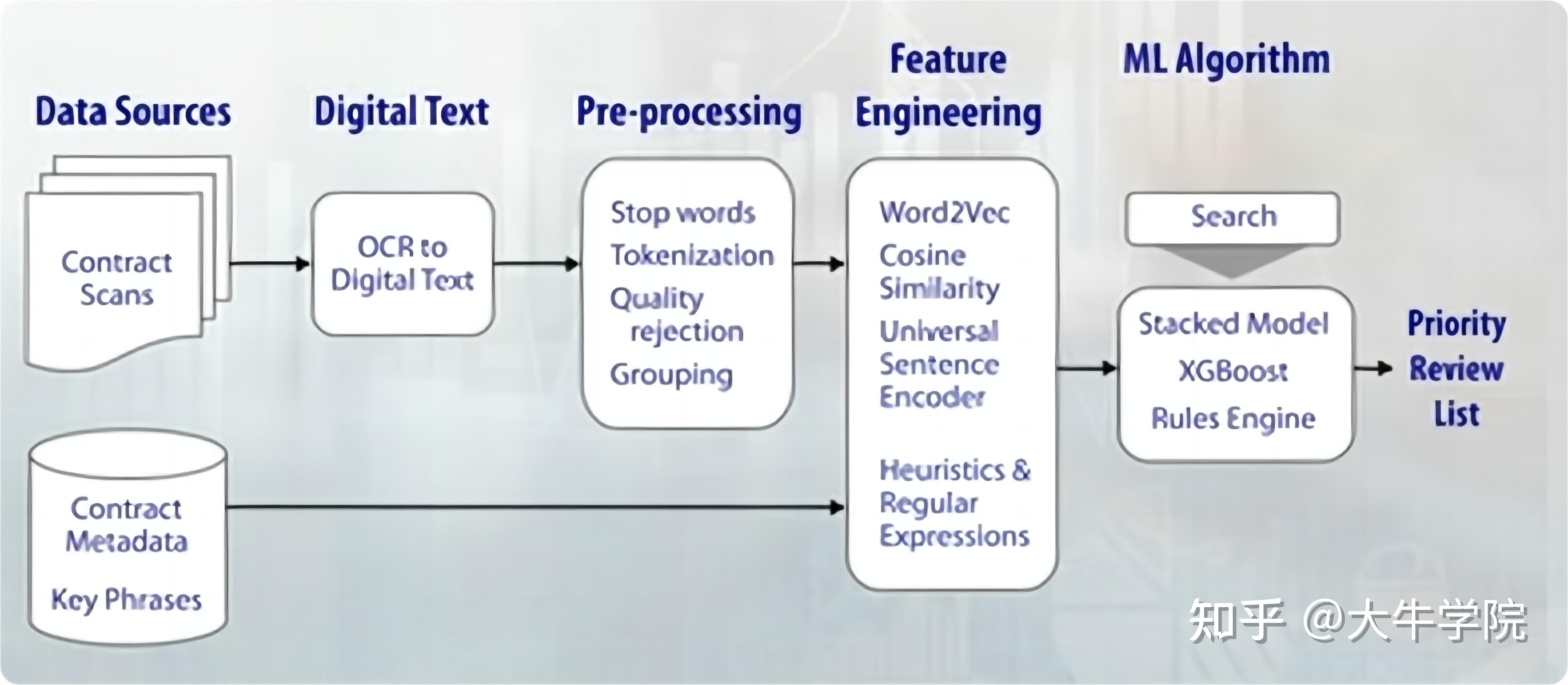
举一个我最近做的项目:要分类Google Books上面成百上千的法律合同文件。这些文件都有他们的特殊性质和特征。这个项目的目的是方便律师们进行阅读和信息筛选,让他们对于一些特定的信息进行搜索和相关条款的使用。因为传统人工的机遇这样信息审核太慢也会有缺失而且还贵,因此我们选择NLP来完成这个任务!
因此,机智的你通过公司首先快速收集到了很多合同的扫描文件信息和文件的元数据,这些信息包括了交易双方信息,日期和关键短语。然后我们可以使用文本扫描技术(OCR)来对整个信息转化成为电脑使用的文本数据。
但这一步仍然不是很成熟,所以会有很多图像识别的噪声和拼写错误。那我们就可以加入预处理的步骤来纠正这些错误,并且减少我们整个文本信息的复杂度。这一步根据实际情况需要,可能有很多步骤处理,暂且不表,我们进入特征识别和模型训练部分。我们发现很多的合同数据并没有标识数据,这对于传统机器学习方法就是一个挑战。那么这时候我们就有两条路可以选:
1. 选择一个主题模型算法,能够把文档分割归类。我们就可以用很成熟的算法库来实现。但是这也会造成我们需要进行多次评估和迭代,因为这些主题的归类预测往往需要对模型参数进行调整。
2. 我们返回之前的步骤,去人工标识这些数据,然后再用于训练。这样我们就可以利用每个提供合同文件的律师的工作范围来进一步细化这个模型识别。我们还可以在模型训练时加入约束,加入一些法律条款和合同的特性,来提升模型的专业性并进行更好的识别。接着我们就可以使用不同的算法,比如XGBoost来大范围的进行搜索和训练测试。最后我们就可以应用这个模型实现一个合同具体信息检索和目标提取。
NLP是一个充满挑战但又极具潜力的领域,快速入门需要理论与实际结合,不断学习和实践。希望这篇文章能帮助你迈出第一步!
<hr/>PS:附一个我自学NLP时总结的学习路径和资源
第一步:基础编程和数学知识
1.1 学习Python编程
Python是NLP的主要编程语言之一,掌握它是迈向NLP的第一步。
• Python基础教程:Python 官方文档,系统地介绍了Python编程的基础知识。
• Codecademy Python课程:交互式学习平台,适合初学者循序渐进地学习Python。
1.2 学习基础数学和统计学
统计学和数学是理解和应用NLP算法的基础。
• Khan Academy 数学课程:提供全面的数学课程,从基础到高级数学。
• Coursera 统计学基础:密歇根大学开设的课程,讲解统计学的基本概念和方法。
第二步:了解NLP基础
2.1 学习NLP基础概念
在了解NLP的基本概念和原理后,你会对这个领域有一个总体的认识。
• Coursera: 自然语言处理导论:密歇根大学的入门课程,覆盖了NLP的基础知识和应用。
• Dan Jurafsky 和 Chris Manning 的视频系列:两位NLP专家的系列视频,深入浅出地讲解NLP的各种概念和技术。
第三步:实践NLP基础任务
3.1 练习文本预处理
文本预处理是NLP工作流程中的重要一步,它涉及清洗和准备数据。
• Natural Language Toolkit (NLTK):一个广泛使用的Python库,提供了丰富的文本处理工具和教程。
• spaCy:另一个强大的Python库,专注于高效的自然语言处理,提供了详细的文档和示例。
3.2 进行简单的文本分类和情感分析
通过简单的NLP任务来加深对概念的理解。
• Kaggle: 自然语言处理入门课程:Kaggle提供的在线课程,结合实际数据集进行学习和实践。
第四步:深度学习和高级NLP
4.1 学习深度学习基础
深度学习是现代NLP模型的重要组成部分。
• Coursera: 深度学习专业课程:由深度学习专家Andrew Ng教授讲授的系列课程,涵盖了深度学习的基本原理和实践。
• fast.ai 深度学习课程:实用的深度学习课程,强调动手实践和快速应用。
4.2 探索高级NLP模型和技术
掌握深度学习后,可以进一步学习和应用高级NLP技术。
• Stanford CS224d: 深度学习与自然语言处理:斯坦福大学的高级课程,深入讲解深度学习在NLP中的应用。
• Hugging Face 变形金刚模型教程:详细介绍了如何使用和训练现代NLP模型,如BERT和GPT。
第五步:项目实践与应用
5.1 开始实际项目
实际项目是将理论应用于实践的最佳方式。
• 建议项目:
• 实现一个简单的聊天机器人
• 构建一个新闻分类器
• 开发一个情感分析工具
5.2 参与开源项目和社区
开源项目和社区是学习和成长的重要平台。
• GitHub上的NLP项目:浏览并参与NLP相关的开源项目。
• Hugging Face社区 和 spaCy社区:加入社区,参与讨论和贡献代码。
学习资源整合
• Coursera: Introduction to Natural Language Processing:密歇根大学的NLP导论课程,适合初学者。
• Stanford CS224d: Deep Learning for Natural Language Processing:斯坦福大学的高级课程,适合有一定基础的学习者。
• fast.ai: Practical Deep Learning for Coders:实用的深度学习课程,强调动手实践和快速应用。
• spaCy:高效的NLP Python库,提供丰富的文档和示例。
• NLTK:经典的NLP Python库,适合教学和研究。
• Hugging Face:现代NLP模型和工具,提供丰富的教程和社区支持。 |
|




















