dos700 LV
发表于 2025-4-22 16:12:29
DeepSeekv3 由幻方量化自主研发,具备“大规模硬件投入、底层训练框架自研、完全开源”三大鲜明特征。与主流大模型(如 OpenAI、Meta、百度文心一言、智谱 GLM、阿里 Qwen)不同,DeepSeekv3 并未急于商业化,而是将焦点放在“超长期主义”的底层技术深耕,宣称在部分评测中可超越 ChatGPT-4.0。本文将系统介绍 DeepSeekv3 的技术路线与策略,分析其优劣与面临的产业挑战,并结合国内外大模型开源生态现状,对其发展前景做出多维度评估。我们将从技术发展规律、行业生态、商业模式与社会影响等层面,探讨 DeepSeekv3 技术路线的“正确性”,以及在国内外竞争格局下的可能定位。
1. 引言:大模型竞赛的多元格局
1.1 大模型的全球繁荣与国内现状
自 GPT-3 以来,大语言模型(LLM)的参数规模与应用潜能出现爆炸式增长。OpenAI、Meta 等海外巨头通过庞大算力与海量数据,将大模型推向超大规模。国内也陆续出现多家自主或合作研发的模型项目(如百度文心一言、智谱 GLM、阿里巴巴 Qwen 等),在中文对话、行业应用等场景取得一定进展。但在整体生态与社区影响力方面,海外依然占据主导。
1.2 DeepSeekv3 的出现与独特定位
DeepSeekv3 由量化投资机构幻方量化自研,最大特点在于“三大要素”:
1. 大规模硬件:率先购入英伟达 V100、A100 等高端 GPU,搭建超大算力集群;
2. 自研底层框架:在分布式训练、内存优化、调度管理等方面深度定制;
3. 完全开源:公开模型权重与训练代码,鼓励社区自由使用和二次开发。
其背后理念是“超长期主义”——当下并未大规模商业化,而是将资源聚焦于底层基建和长期竞争力上。然而,这种思路也引发诸多争议与质疑:短期盈利模式缺失、完全开源是否会削弱竞争壁垒、对英伟达 GPU 的重度依赖能否持续等。尽管如此,DeepSeekv3 依然在部分测试中呈现出竞争力,且在中国开源大模型尚未形成全球影响力的环境中,探索出一条与众不同的发展路线。
2. 技术路线:大规模硬件与自主训练框架
2.1 大模型核心需求与发展趋势
大模型的性能在很大程度上取决于以下因素:
• 参数规模:从十亿级到千亿甚至万亿级,模型可拥有更强的理解与生成能力;
• 数据质量与多样性:训练语料的丰富性与干净度,直接影响模型泛化水平;
• 算力投入:对 GPU/TPU 等硬件资源的需求呈指数级增长,训练过程繁琐且成本高昂;
• 推理优化:模型落地时,如何在推理阶段实现低延迟、高吞吐和可扩展性是关键。
2.2 DeepSeekv3 的自研框架与算力优势
1. 自研框架
幻方量化根据大语言模型的特定需求,对分布式训练、并行调度、数据流水线、混合精度计算等做了针对性研发,相比依赖纯开源框架(如 PyTorch、TensorFlow、deepspeed),更能灵活优化集群资源、提高训练效率。
2. 英伟达 GPU 大规模投入
DeepSeekv3 早期购入大量 V100、A100 乃至后期的 H800,形成了庞大的 GPU 集群,对大模型训练中“算力短板”做了前瞻性布局。这在短期内确实支撑了 DeepSeekv3 的快速迭代,也为其在金融量化业务上带来“隐性回报”。
3. 推理端极低成本
通过模型量化(INT8、INT4)、独特的MLA、MOE等手段来降低推理阶段的资源占用;并利用分层缓存或并行策略保证推理响应速度与吞吐量。然而,这些手段也存在一定精度损耗或工程复杂度,需要针对不同场景平衡。
3. 完全开源与超长期主义
3.1 开源策略的内涵与挑战
DeepSeekv3 将核心代码、模型权重对外全部开放,目的是借力全球开发者和研究者的力量,快速迭代和演进。
• 优势:低门槛,吸引更多贡献者加入,可“以小搏大”形成社区效应;
• 劣势:缺乏商业护城河,竞争对手可轻松借鉴技术成果,若无持续资源投入,易陷入“有名无实”的境地。
3.2 “超长期主义”与短期盈利难题
DeepSeekv3 并未像 OpenAI、百度、阿里那样在短期内大规模推行商业化,而是依托幻方量化的内部资金与金融收入支撑巨额研发费用。
• 策略合理性:若 AI 替代人工的临界点尚未到来,提前深耕算力与底层算法有可能在未来形成难以撼动的壁垒。
• 风险:假如行业技术或市场竞争节奏变化快,DeepSeekv3 若错失关键应用落地期,可能面临资金链与影响力的双重难题。
4. 与主流大模型的对比:OpenAI、Meta、百度、智谱、阿里 Qwen
4.1 DeepSeekv3 与 OpenAI (GPT-4)
1. 闭源与开源的对立
• OpenAI:GPT-4 保持高度闭源,仅提供 API 访问权限以保护核心技术壁垒,最近的o1模型直接隐藏掉了中间推理过程;
• DeepSeekv3:完全开源,意在吸引更广泛的开发者参与。
2. 商业化路径
• OpenAI:通过 GPT-4 API 收费、ChatGPT Plus 订阅模式实现大规模变现,与微软深度合作推动企业级应用;
• DeepSeekv3:尚无明确的商业化规划,依赖幻方量化内部的资金与金融业务支撑,api的成本也是做到了行业最低。
3. 对比总结
• OpenAI 的路线适合快速变现,但对技术透明度要求高的开发者群体吸引力有限;
• DeepSeekv3 的完全开源更具技术共享价值,但能否吸引国际社区的深度参与仍是未知数。
4.2 DeepSeekv3 与 Meta (Llama 系列)
1. 开源策略
• Meta:Llama 系列采取部分开源策略(如 Llama-2),开放权重并引入许可协议,催生了广受欢迎的 Llama.cpp 、llama-vl、llama-factory、llama-mesh等一系列生态工具;
• DeepSeekv3:同为开源,却未出现类似“llama.cpp”这样的爆款工具,国内与海外社区响应度尚显不足。
2. 生态影响力
• Meta:依托全球社交网络与行业资源,在社区与行业生态中占据主导;
• DeepSeekv3:背靠金融量化机构,国际化生态影响力尚需时间培育。
3. 对比总结
• Meta 的路线显示,开放度与生态建设密切相关;
• DeepSeekv3 在全球化兼容和工具链建设上需要进一步投入。
4.3 DeepSeekv3 与百度文心一言、智谱 GLM、阿里 Qwen
1. 中文场景 vs. 通用场景
• 百度、智谱、阿里:更多依托现有业务生态(搜索、云计算、电商、社交),形成快速落地能力;
• DeepSeekv3:完全开源,但在国内落地推广尚不显著,缺少 B 端或 C 端场景深度结合。
2. 商业化与生态建设
• 百度、智谱、阿里:基于自身庞大的用户与企业客户资源,易于推动行业应用;
• DeepSeekv3:定位通用底层技术,需要额外的社区运营与行业合作来形成规模效应。
3. 对比总结
• 国内大模型更多是“依托业务生态 + 局部开源”,而 DeepSeekv3 则“资源自持 + 完全开源”。
• 若缺乏示范应用,DeepSeekv3 可能难以形成自我造血机能。
5. 国内模型开源与社区发展的困境
5.1 为什么国内开源并未引发大规模技术贡献?
1. 开源模式的局限:国内项目往往缺少系统的文档、示例、社区运营,而是“只放出代码”,难以吸引海外乃至国内开发者深度参与。
2. 多语言适配不足:部分国内模型在英文或多语言上的性能逊色,很难融入全球主流社区;许可协议和知识产权问题也让国外开发者望而却步。
3. 缺少示范性应用:像 Llama.cpp 这类“即插即用”“轻量部署”的引擎在国内尚未火爆,难以形成下游生态的爆发点。
5.2 DeepSeekv3 如何突围?
• 兼容海外工具链:在语言与技术工具上对接 Hugging Face、C++/Rust 推理优化等国际通用生态,降低使用门槛;
• 行业化特色:将其金融量化的独特应用案例包装成模板,让外部对 DeepSeekv3 在高价值领域的效果有更直观理解,从而吸引专业开发者与机构进驻;
• 持续社区投入:建立官方文档、示例工程、论坛和优质教程,为开发者提供“点对点”的支持。
6. 英伟达垄断与硬件变局
6.1 依赖 GPU 的瓶颈与潜在风险
DeepSeekv3 对英伟达 GPU 的大规模采购固然带来算力优势,却也面临:
• 硬件成本与供应不确定:英伟达 GPU 价格昂贵,产能有限,且受地缘政治、市场波动影响;
• 国产芯片或谷歌 TPU 的出现:一旦未来出现性价比更优或生态更完整的方案,DeepSeekv3 前期硬件投入可能陷入贬值或闲置。
6.2 对策与生态兼容
• 多硬件兼容:建议 DeepSeekv3 逐步在框架层面实现对非英伟达硬件的兼容测试,以免在竞争性市场中被制约;
• 云端弹性算力:通过与国际或国内云厂商合作,在云平台上为中小团队提供更灵活的训练和部署方案。
7. 商业模式与社会影响
7.1 盈利模式的长程探讨
1. 企业级与政企服务:当大模型在商务、办公、政务等领域需求攀升,DeepSeekv3 可提供定制化解决方案或技术支持服务;
2. 金融业务内循环:幻方量化自身的量化交易、风险控制可能已从 DeepSeekv3 中获益,这部分“隐性回报”或足以支撑项目继续前行;
3. 生态驱动:若社区形成一定规模,可以在增值插件、数据增补、推理加速等领域收费,类似“开源+服务”的模式。
7.2 AI 替代人工与监管挑战
大模型在未来数年或具备更多自动化能力,产生结构性失业风险、算法歧视、数据合规等一系列问题。
• 安全策略与内容审查:DeepSeekv3 在开源社区中需要主动加入安全策略、内容审查等技术模块,为潜在监管要求留出空间;
• 社会配套与监管:社会层面则需建立配套的法规、伦理、再教育机制,减缓 AI 替代的负面冲击。
8. DeepSeekv3 技术路线的正确性及前景评估
8.1 多维度判断
1. 技术演进规律:大规模算力+自研框架在中长期具备竞争力,DeepSeekv3 的路线并无明显悖论;
2. 行业生态:完全开源的定位抓住了开源生态的潜力,但必须在社区运营与应用示范上双管齐下;
3. 商业风险:短期盈利路径模糊,加之英伟达硬件垄断与国内开源文化尚未繁荣,存在极大不确定性。
8.2 可能的关键成功要素
1. 持续投入与组织保障:幻方量化能否保持数年甚至十数年的技术/资金支持,是 DeepSeekv3 超长期主义能否落地的根本;
2. 兼容海外与国内工具链:吸引更多开源贡献者,形成全球生态;
3. 行业应用示范:将金融领域的成功经验复用到其他垂直行业,带动外部用户共建;
4. 硬件多元化:加强对 GPU 以外硬件的适配能力,以降低对单一供应商的风险。
9. 结论:向未来迈进的可能路径
DeepSeekv3 代表了一种“与众不同”的大模型研发思路:不依赖外部商业化压力,也不急于通过 API 或 SaaS 收费来回收成本,而是在幻方量化的内部资金与量化技术之上,构筑自研框架与大规模算力布局,并以完全开源、超长期主义的方式打造 AI 生态。从技术趋势看,此举并不违背大模型发展客观规律;从市场与生态角度看,国内开源大模型尚未形成可比肩 Llama 等国际项目的热潮,DeepSeekv3 能否抓住机会在社区中崛起,仍是未知数。
如若 DeepSeekv3 能在未来三到五年内持续迭代、形成丰富的行业应用示例、并建立起有活力的全球开发者社区,那么其目前“超长期主义”的沉淀或将在大模型全面爆发时获得丰厚回报。反之,若缺乏可持续运营和关键时刻的商业落地,完全开源可能难以转化为核心护城河。市场的激烈竞争和技术迭代速度,也可能令这笔投入变为“沉没成本”。
总体而言,DeepSeekv3 的技术路线具备一定“正确性”与独特价值:深耕算力与自研框架为其提供长期成长空间,开源与超长期主义是一种值得关注的探索。然而,这条道路伴随着相当程度的不确定性和风险,需要更完善的社区策略、更灵活的商业模式以及稳健的资源支持,方能在大模型时代的浪潮里占据一席之地。
参考文献(示例)
1. OpenAI (2023). GPT-4 Technical Report. [Online]. Available: https://openai.com/
2. Meta AI (2023). Llama: Open and Efficient Foundation Language Models. [Online]. Available: https://ai.facebook.com/tools/llama
3. 百度 AI (2023). 文心一言(ERNIE Bot)技术白皮书. [Online]. Available: https://cloud.baidu.com/
4. 智谱 AI (2023). GLM & ChatGLM 系列模型文档. [Online]. Available: https://github.com/THUDM
5. 阿里云 (2023). Qwen(通义千问)研发与应用介绍. [Online]. Available: https://www.aliyun.com/
6. Brown, M. et al. (2021). “An Overview of Large Language Models: Techniques, Trends, and Transformation,” Journal of AI Research, 45(3), 102–118.
7. Zhang, K. et al. (2022). “Quantization and Pruning in AI Model Deployment,” IEEE Transactions on Neural Networks, 39(7), 541–555.
8. NVIDIA (2023). CUDA Toolkit Documentation. [Online]. Available: https://developer.nvidia.com/cuda-toolkit
9. 幻方量化 (2023). DeepSeekv3 开源项目主页. [GitHub]. |
|

 个head(图中为8个),为了节省计算需要缓存的KV数量可以表示为
个head(图中为8个),为了节省计算需要缓存的KV数量可以表示为 其中
其中  代表已经生成的token数量,
代表已经生成的token数量,  则代表每个头K向量的维度。
则代表每个头K向量的维度。 ,最终的KV数变为
,最终的KV数变为  。虽然MQA极大地减少了长序列文本计算需要缓存的KV数量,但在性能下降上也较为明显。
。虽然MQA极大地减少了长序列文本计算需要缓存的KV数量,但在性能下降上也较为明显。


 将输入的embedding转化为Q、K、V三个矩阵,经过转化的Q、K、V矩阵和原输入的维度是相同的,都为[seq_length, embedding_dim]。然而MLA将这一步变为了向下投影,最终的得到的维度为[seq_length, latent_dim],latent_dim的大小会远小于embedding_dim。过程计算公式如下:
将输入的embedding转化为Q、K、V三个矩阵,经过转化的Q、K、V矩阵和原输入的维度是相同的,都为[seq_length, embedding_dim]。然而MLA将这一步变为了向下投影,最终的得到的维度为[seq_length, latent_dim],latent_dim的大小会远小于embedding_dim。过程计算公式如下:
 代表向下投影的意思,
代表向下投影的意思,  代表输入的embedding向量。
代表输入的embedding向量。 第三步: 对Q、K应用旋转位置编码(RoPE),并进行拼接。RoPE主要是为了应对长文本序列时保持相对位置信息,在这里不需要深入了解,你只需要知道它是一种位置编码技术,过程公式计算如下:
第三步: 对Q、K应用旋转位置编码(RoPE),并进行拼接。RoPE主要是为了应对长文本序列时保持相对位置信息,在这里不需要深入了解,你只需要知道它是一种位置编码技术,过程公式计算如下: 
 。过程公式计算如下:
。过程公式计算如下: 
 降低到lantent_dim的维度,显著减少显存占用。
降低到lantent_dim的维度,显著减少显存占用。 直接对其应用RoPE:
直接对其应用RoPE: 此时的QK点积为:
此时的QK点积为: 当需要将权重矩阵
当需要将权重矩阵  和
和  合并时(矩阵吸收),因为
合并时(矩阵吸收),因为  是位置相关的旋转矩阵,无法实现下面的交换律:
是位置相关的旋转矩阵,无法实现下面的交换律: 旋转矩阵
旋转矩阵  来预先计算旋转基向量,主分支保持线性变化
来预先计算旋转基向量,主分支保持线性变化  最终K向量重构为:
最终K向量重构为: 所以点积变化为:
所以点积变化为: 这与原始的RoPE等效,所以如图所示,最终MLA只需要缓存潜向量
这与原始的RoPE等效,所以如图所示,最终MLA只需要缓存潜向量  和k对应的旋转位置编码结果
和k对应的旋转位置编码结果  。其中计算量也会大大减少。按照初始维度为4096,中间潜向量维度为512的情况,计算量差别如下:
。其中计算量也会大大减少。按照初始维度为4096,中间潜向量维度为512的情况,计算量差别如下:
 对MoE层很重要,该MoE网络使用softmax激活函数建模,使用指令分配传入token的每个专家的权重,详细计算如下:
对MoE层很重要,该MoE网络使用softmax激活函数建模,使用指令分配传入token的每个专家的权重,详细计算如下: 其中
其中  是MoE层的输入标记,
是MoE层的输入标记,  和
和  是前馈层(FFN)的输入和输出的投影矩阵。矢量
是前馈层(FFN)的输入和输出的投影矩阵。矢量  由门控网络计算,
由门控网络计算, 
 ,然后专家的数量扩展为原来的
,然后专家的数量扩展为原来的  倍,推理的时候路由专家的数量也增加为原来的
倍,推理的时候路由专家的数量也增加为原来的  个,总专家数为
个,总专家数为  个,路由专家总数为
个,路由专家总数为  个,推理激活使用的路由专家总数为
个,推理激活使用的路由专家总数为  个。
个。

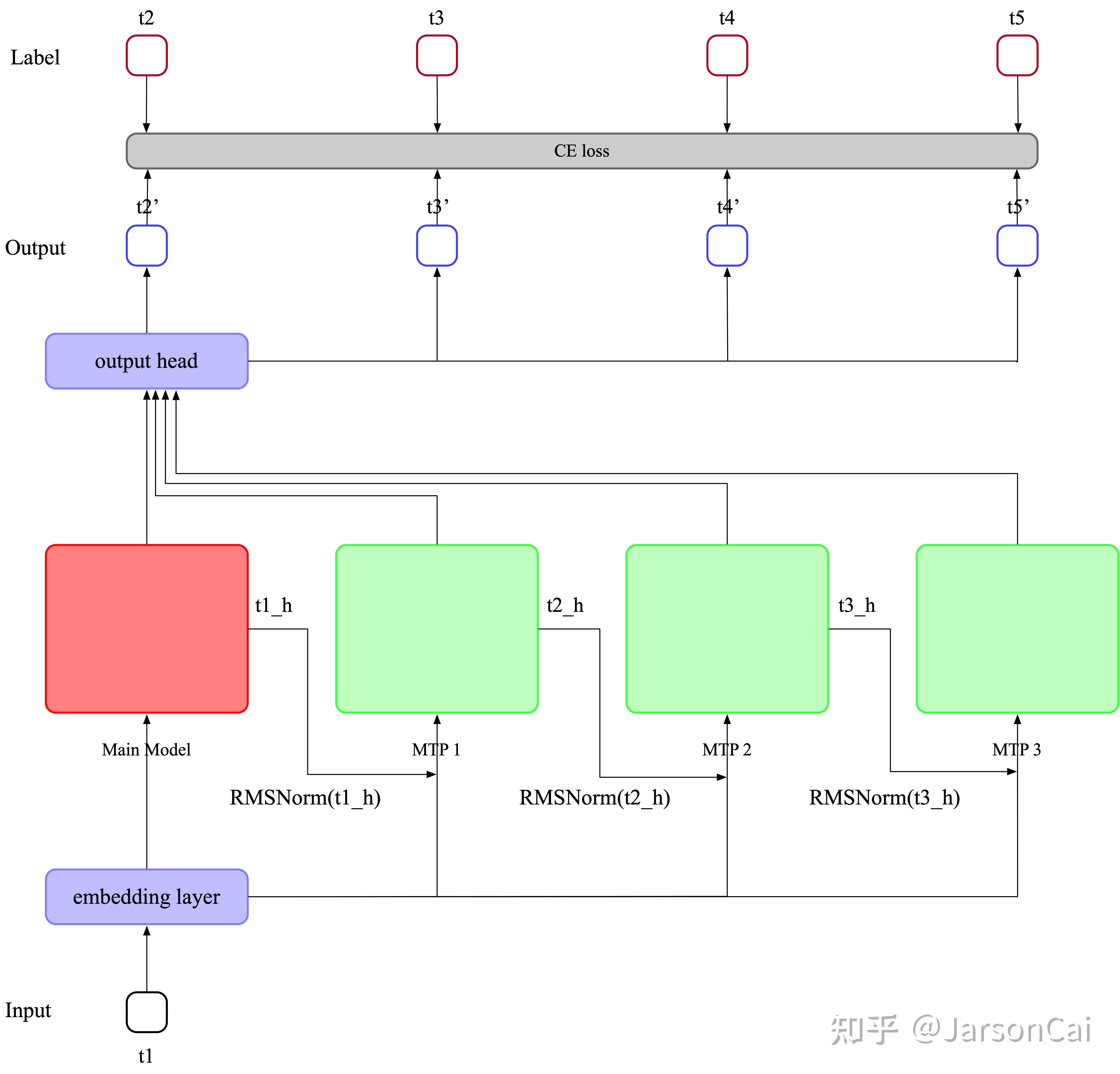
 个token
个token  ,预测深度为
,预测深度为  。预测第
。预测第  个token,隐藏层维度为
个token,隐藏层维度为  。
。 个输入token通过一层共享的embedding layer
个输入token通过一层共享的embedding layer 层(上一层)的隐藏层输出做归一化处理RMSNorm
层(上一层)的隐藏层输出做归一化处理RMSNorm 位置的token embedding做归一化处理
位置的token embedding做归一化处理 重新减为
重新减为