案例
虽然7B模型,但显存吃的还是很大
官方视频案例【https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4】,21秒视频,显示显存100GB显存OOM:
图片稍大就保错,现在官方demo也是这个问题:
速度很慢,不知道是我没配置好还是其他原因,一次要三四分钟才能生成语音(没有flash-att加速);
案例1 (图+文)生成 (音)
一张小图,语音生成是ok的;
生成结果还是ok的,但是还是玩的不够尽兴;
案例2 (文) 生 (语音)
还是东北腔的;
后面测试更多的结果;
方法
模型框架
这个模型框架好复杂,还没自习看transformers内部代码:- Qwen2_5OmniModel(
- (thinker): Qwen2_5OmniThinkerForConditionalGeneration(
- (audio_tower): Qwen2_5OmniAudioEncoder(
- (conv1): Conv1d(128, 1280, kernel_size=(3,), stride=(1,), padding=(1,))
- (conv2): Conv1d(1280, 1280, kernel_size=(3,), stride=(2,), padding=(1,))
- (positional_embedding): SinusoidsPositionEmbedding()
- (audio_bos_eos_token): Embedding(2, 3584)
- (layers): ModuleList(
- (0-31): 32 x Qwen2_5OmniAudioEncoderLayer(
- (self_attn): Qwen2_5OmniAudioAttention(
- (k_proj): Linear(in_features=1280, out_features=1280, bias=False)
- (v_proj): Linear(in_features=1280, out_features=1280, bias=True)
- (q_proj): Linear(in_features=1280, out_features=1280, bias=True)
- (out_proj): Linear(in_features=1280, out_features=1280, bias=True)
- )
- (self_attn_layer_norm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
- (activation_fn): GELUActivation()
- (fc1): Linear(in_features=1280, out_features=5120, bias=True)
- (fc2): Linear(in_features=5120, out_features=1280, bias=True)
- (final_layer_norm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
- )
- )
- (ln_post): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
- (avg_pooler): AvgPool1d(kernel_size=(2,), stride=(2,), padding=(0,))
- (proj): Linear(in_features=1280, out_features=3584, bias=True)
- )
- (visual): Qwen2_5OmniVisionEncoder(
- (patch_embed): Qwen2_5_VisionPatchEmbed(
- (proj): Conv3d(3, 1280, kernel_size=(2, 14, 14), stride=(2, 14, 14), bias=False)
- )
- (rotary_pos_emb): Qwen2_5_VisionRotaryEmbedding()
- (blocks): ModuleList(
- (0-31): 32 x Qwen2_5OmniVisionBlock(
- (norm1): Qwen2RMSNorm((1280,), eps=1e-06)
- (norm2): Qwen2RMSNorm((1280,), eps=1e-06)
- (attn): Qwen2_5OmniVisionAttention(
- (q): Linear(in_features=1280, out_features=1280, bias=True)
- (k): Linear(in_features=1280, out_features=1280, bias=True)
- (v): Linear(in_features=1280, out_features=1280, bias=True)
- (proj): Linear(in_features=1280, out_features=1280, bias=True)
- )
- (mlp): Qwen2_5OmniMLP(
- (gate_proj): Linear(in_features=1280, out_features=3420, bias=True)
- (up_proj): Linear(in_features=1280, out_features=3420, bias=True)
- (down_proj): Linear(in_features=3420, out_features=1280, bias=True)
- (act_fn): SiLU()
- )
- )
- )
- (merger): Qwen2_5OmniPatchMerger(
- (ln_q): Qwen2RMSNorm((1280,), eps=1e-06)
- (mlp): Sequential(
- (0): Linear(in_features=5120, out_features=5120, bias=True)
- (1): GELU(approximate='none')
- (2): Linear(in_features=5120, out_features=3584, bias=True)
- )
- )
- )
- (model): Qwen2_5OmniThinkerModel(
- (embed_tokens): Embedding(152064, 3584)
- (layers): ModuleList(
- (0-27): 28 x Qwen2_5OmniDecoderLayer(
- (self_attn): Qwen2_5OmniAttention(
- (q_proj): Linear(in_features=3584, out_features=3584, bias=True)
- (k_proj): Linear(in_features=3584, out_features=512, bias=True)
- (v_proj): Linear(in_features=3584, out_features=512, bias=True)
- (o_proj): Linear(in_features=3584, out_features=3584, bias=False)
- (rotary_emb): Qwen2_5OmniRotaryEmbedding()
- )
- (mlp): Qwen2MLP(
- (gate_proj): Linear(in_features=3584, out_features=18944, bias=False)
- (up_proj): Linear(in_features=3584, out_features=18944, bias=False)
- (down_proj): Linear(in_features=18944, out_features=3584, bias=False)
- (act_fn): SiLU()
- )
- (input_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
- (post_attention_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
- )
- )
- (norm): Qwen2RMSNorm((3584,), eps=1e-06)
- (rotary_emb): Qwen2_5OmniRotaryEmbedding()
- )
- (lm_head): Linear(in_features=3584, out_features=152064, bias=False)
- )
- (talker): Qwen2_5OmniTalkerForConditionalGeneration(
- (thinker_to_talker_proj): Linear(in_features=3584, out_features=896, bias=True)
- (model): Qwen2_5OmniTalkerModel(
- (embed_tokens): Embedding(8448, 3584)
- (layers): ModuleList(
- (0-23): 24 x Qwen2_5OmniDecoderLayer(
- (self_attn): Qwen2_5OmniAttention(
- (q_proj): Linear(in_features=896, out_features=1536, bias=True)
- (k_proj): Linear(in_features=896, out_features=512, bias=True)
- (v_proj): Linear(in_features=896, out_features=512, bias=True)
- (o_proj): Linear(in_features=1536, out_features=896, bias=False)
- (rotary_emb): Qwen2_5OmniRotaryEmbedding()
- )
- (mlp): Qwen2MLP(
- (gate_proj): Linear(in_features=896, out_features=18944, bias=False)
- (up_proj): Linear(in_features=896, out_features=18944, bias=False)
- (down_proj): Linear(in_features=18944, out_features=896, bias=False)
- (act_fn): SiLU()
- )
- (input_layernorm): Qwen2RMSNorm((896,), eps=1e-06)
- (post_attention_layernorm): Qwen2RMSNorm((896,), eps=1e-06)
- )
- )
- (norm): Qwen2RMSNorm((896,), eps=1e-06)
- (rotary_emb): Qwen2_5OmniRotaryEmbedding()
- )
- (codec_head): Linear(in_features=896, out_features=8448, bias=False)
- )
- (token2wav): Qwen2_5OmniToken2WavModel(
- (code2wav_dit_model): Qwen2_5OmniToken2WavDiTModel(
- (time_embed): TimestepEmbedding(
- (time_embed): SinusPositionEmbedding()
- (time_mlp): ModuleList(
- (0): Linear(in_features=256, out_features=1024, bias=True)
- (1): SiLU()
- (2): Linear(in_features=1024, out_features=1024, bias=True)
- )
- )
- (text_embed): CodecEmbedding(
- (codec_embed): Embedding(8194, 512)
- )
- (input_embed): InputEmbedding(
- (proj): Linear(in_features=912, out_features=1024, bias=True)
- (spk_encoder): ECAPA_TDNN(
- (blocks): ModuleList(
- (0): TDNNBlock(
- (conv): Conv1d(80, 256, kernel_size=(5,), stride=(1,), padding=same, padding_mode=reflect)
- (activation): ReLU()
- )
- (1-3): SERes2NetBlock(
- (tdnn1): TDNNBlock(
- (conv): Conv1d(256, 256, kernel_size=(1,), stride=(1,), padding=same, padding_mode=reflect)
- (activation): ReLU()
- )
- (res2net_block): Res2NetBlock(
- (blocks): ModuleList(
- (0): TDNNBlock(
- (conv): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=same, dilation=(2,), padding_mode=reflect)
- (activation): ReLU()
- )
- )
- )
- (tdnn2): TDNNBlock(
- (conv): Conv1d(256, 256, kernel_size=(1,), stride=(1,), padding=same, padding_mode=reflect)
- (activation): ReLU()
- )
- (se_block): SEBlock(
- (conv1): Conv1d(256, 64, kernel_size=(1,), stride=(1,), padding=same, padding_mode=reflect)
- (relu): ReLU(inplace=True)
- (conv2): Conv1d(64, 256, kernel_size=(1,), stride=(1,), padding=same, padding_mode=reflect)
- (sigmoid): Sigmoid()
- )
- )
- )
- (mfa): TDNNBlock(
- (conv): Conv1d(768, 768, kernel_size=(1,), stride=(1,), padding=same, padding_mode=reflect)
- (activation): ReLU()
- )
- (asp): AttentiveStatisticsPooling(
- (tdnn): TDNNBlock(
- (conv): Conv1d(2304, 64, kernel_size=(1,), stride=(1,), padding=same, padding_mode=reflect)
- (activation): ReLU()
- )
- (tanh): Tanh()
- (conv): Conv1d(64, 768, kernel_size=(1,), stride=(1,), padding=same, padding_mode=reflect)
- )
- (fc): Conv1d(1536, 128, kernel_size=(1,), stride=(1,), padding=same, padding_mode=reflect)
- )
- )
- (rotary_embed): RotaryEmbedding()
- (transformer_blocks): ModuleList(
- (0-21): 22 x DiTBlock(
- (attn_norm): AdaLayerNormZero(
- (silu): SiLU()
- (linear): Linear(in_features=1024, out_features=6144, bias=True)
- (norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=False)
- )
- (attn): DiTAttention(
- (to_q): Linear(in_features=1024, out_features=1024, bias=True)
- (to_k): Linear(in_features=1024, out_features=1024, bias=True)
- (to_v): Linear(in_features=1024, out_features=1024, bias=True)
- (to_out): ModuleList(
- (0): Linear(in_features=1024, out_features=1024, bias=True)
- (1): Dropout(p=0.1, inplace=False)
- )
- )
- (ff_norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=False)
- (ff): FeedForward(
- (ff): ModuleList(
- (0): Linear(in_features=1024, out_features=2048, bias=True)
- (1): GELU(approximate='tanh')
- (2): Dropout(p=0.1, inplace=False)
- (3): Linear(in_features=2048, out_features=1024, bias=True)
- )
- )
- )
- )
- (norm_out): AdaLayerNormZero_Final(
- (silu): SiLU()
- (linear): Linear(in_features=1024, out_features=2048, bias=True)
- (norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=False)
- )
- (proj_out): Linear(in_features=1024, out_features=80, bias=True)
- )
- (code2wav_bigvgan_model): Qwen2_5OmniToken2WavBigVGANModel(
- (conv_pre): Conv1d(80, 1536, kernel_size=(7,), stride=(1,), padding=(3,))
- (ups): ModuleList(
- (0-5): ModuleList(
- (0): ConvTranspose1d(1536, 768, kernel_size=(11,), stride=(5,), padding=(3,))
- )
- )
- (resblocks): ModuleList(
- (0-17): AMPBlock(
- (convs1): ModuleList(
- (0): Conv1d(768, 768, kernel_size=(3,), stride=(1,), padding=(1,))
- (1): Conv1d(768, 768, kernel_size=(3,), stride=(1,), padding=(3,), dilation=(3,))
- (2): Conv1d(768, 768, kernel_size=(3,), stride=(1,), padding=(5,), dilation=(5,))
- )
- (convs2): ModuleList(
- (0-2): 3 x Conv1d(768, 768, kernel_size=(3,), stride=(1,), padding=(1,))
- )
- (activations): ModuleList(
- (0-5): 6 x TorchActivation1d(
- (act): SnakeBeta()
- (upsample): UpSample1d()
- (downsample): DownSample1d()
- )
- )
- )
- )
- (activation_post): TorchActivation1d(
- (act): SnakeBeta()
- (upsample): UpSample1d()
- (downsample): DownSample1d()
- )
- (conv_post): Conv1d(24, 1, kernel_size=(7,), stride=(1,), padding=(3,), bias=False)
- )
- )
- )
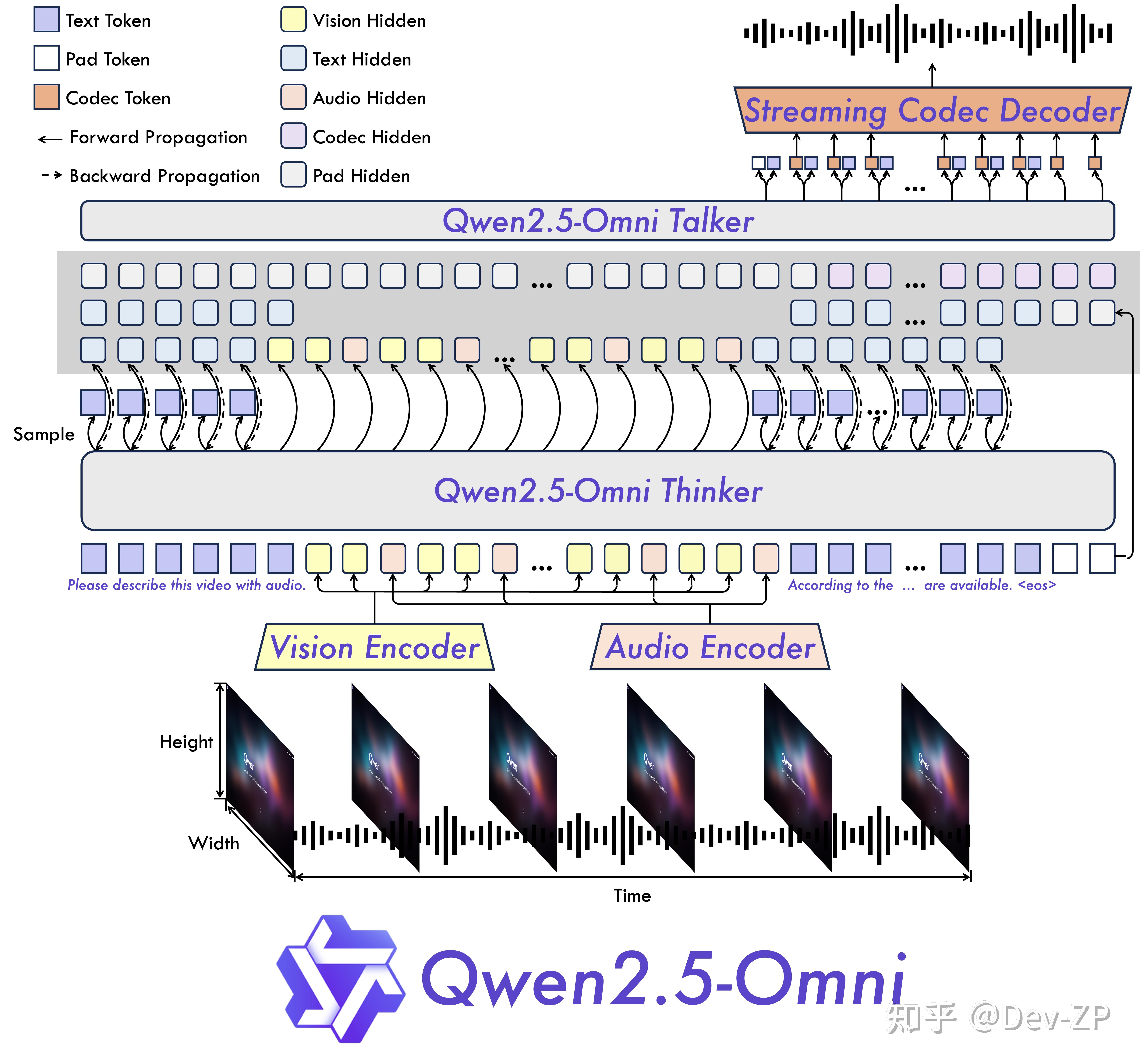
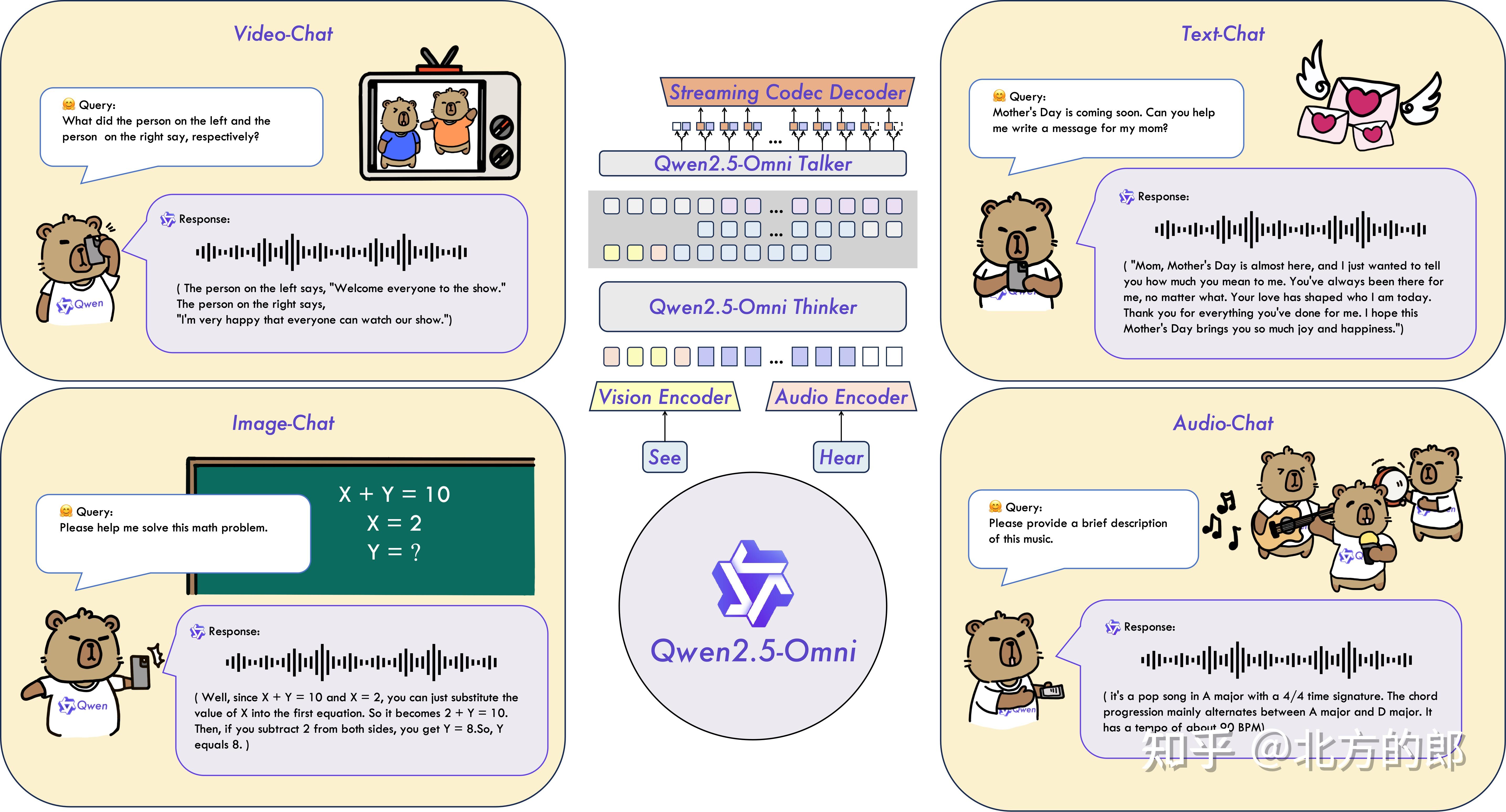
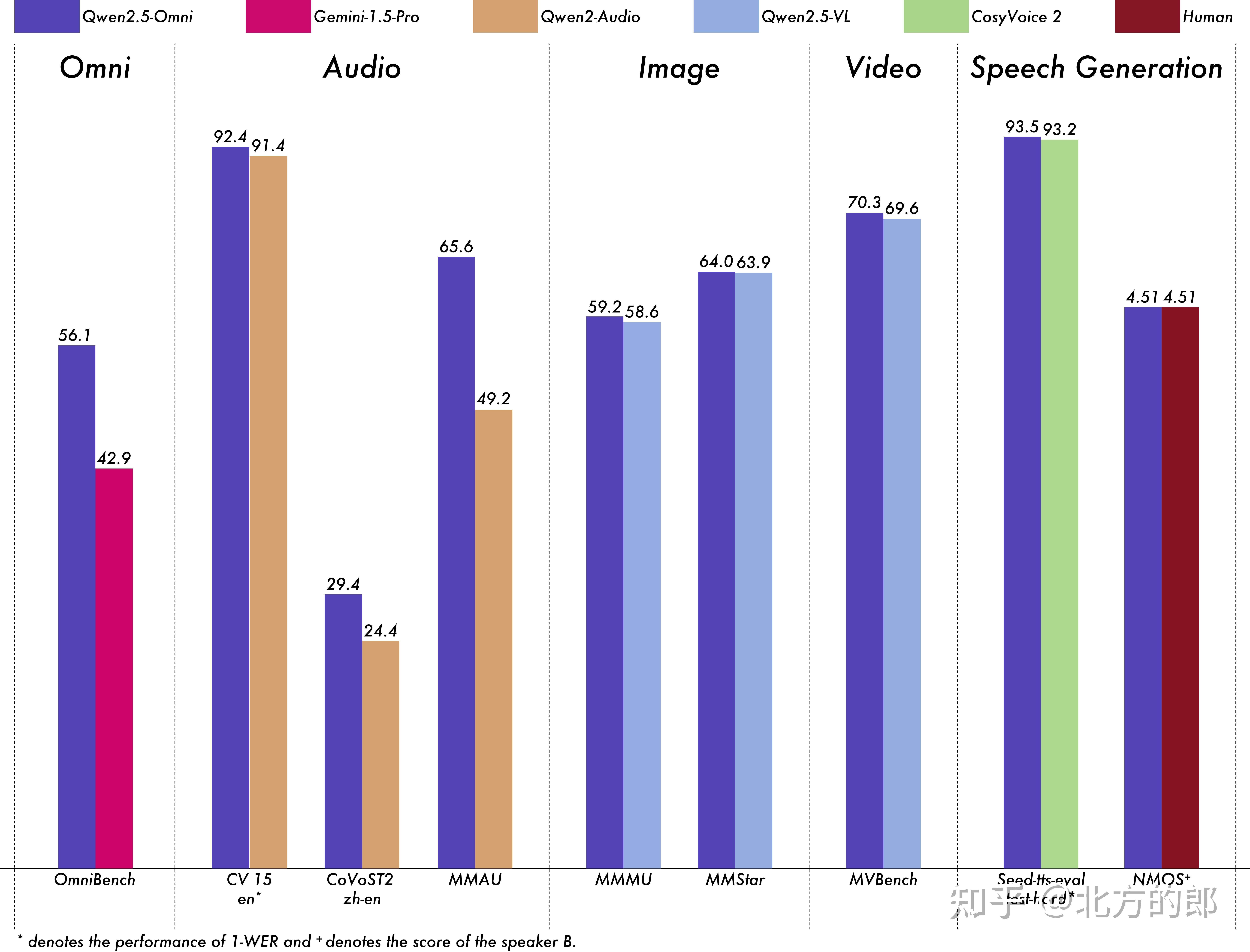
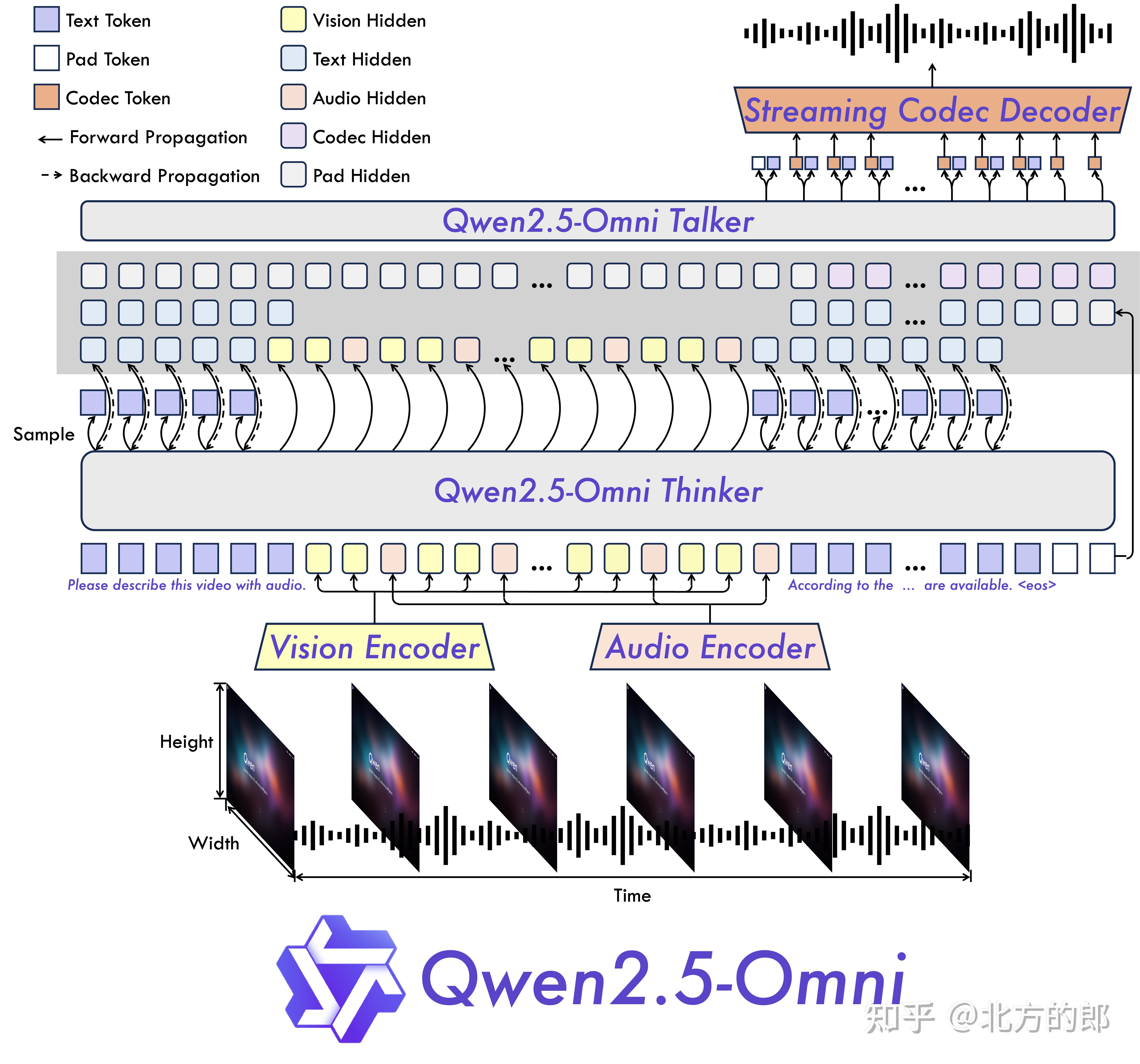
全新的思考者 - 说话者架构
Qwen2.5-Omni 引入了独特的 Thinker-Talker 架构,这是一套端到端的多模态模型,能够处理文本、图像、音频和视频等多种输入形式,并以自然流畅的方式生成文本和语音回应。更令人称道的是,它采用了名为 TMRoPE(时间对齐多模态 RoPE)的新型位置嵌入技术,巧妙地解决了视频输入与音频时间戳同步的难题。这种创新使得模型在处理复杂多模态信息时更加精准高效,为用户带来前所未有的交互体验。 |
|